434(1): デフォルトの名無しさん [sage] 2019/06/10(月) 11:14:02.36 ID:DwfAnHcn(1/4) AAS
>>433
最後のは不正では。
⿰⿱山上下なら
↓こんな文字になっちゃう
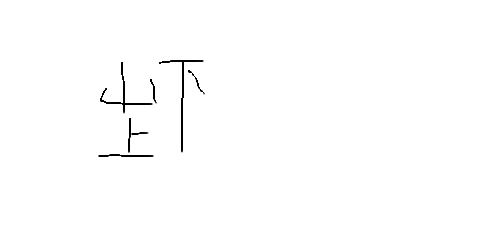
>>433
最後のは不正では。
⿰⿱山上下なら
↓こんな文字になっちゃう
より正確に言えば、133(1): ◆QZaw55cn4c [sage] 2019/01/22(火) 02:34:15.81 ID:zFHfz07h(2/2) AAS
>>132
現に存在するUTF-32/UTF-8 という文字コードの集合を使用した場合に日本語と中国語の漢字を
?:同一文書に含ませることは可能でしょうか??:?が可能であったとして、PC の画面にて同時に表示することは可能でしょうか?
あらゆる言語とは言うけど、縄文時代の日本語を混在させるのは無理だと思うがなあ131(5): ◆QZaw55cn4c [sage] 2019/01/22(火) 01:05:00.00 ID:zFHfz07h(1/2) AAS
漢字コードのことでわからなくなりましたので質問いたします。
よろしくお願いいたします。
外部リンク[html]:pc.watch.impress.co.jp
>文字データをシフトJISではなく、Unicodeで保存するとどんないいことがあるのか。
>たとえばUnicodeならあらゆる言語の文字を混在させることができる。
>Wordでしか文書を書かないエンドユーザーにはそんなこと当たり前じゃないかと言われそうだが、
これって本当ですか?
私見では日本語の漢字と中国語の漢字を同一文書にて同時に表示できないし混在もできない、と思っていたんですが…。
CJK 漢字統合の影響はもう過去の話になってしまったんでしょうか?
みたいな字形になる。434(1): デフォルトの名無しさん [sage] 2019/06/10(月) 11:14:02.36 ID:DwfAnHcn(1/4) AAS
>>433
最後のは不正では。
⿰⿱山上下なら
↓こんな文字になっちゃう
それは理由が書いてないから、読む価値ある?598(1): デフォルトの名無しさん [] 2019/08/31(土) 15:35:30.15 ID:SHne0DDt(2/2) AAS
6 仕様書無しさん sage 2019/08/31(土) 11:36:13.12
日本人ならUTF16を掲げるJavaを支持すべきだ
> UTF8は可変長だから、32ビットでも表そう思えば表せる。616(1): デフォルトの名無しさん [] 2019/09/01(日) 13:42:43.07 ID:k0czTyLP(2/3) AAS
>>612
>まずUTF-16という仕様にはサロゲートペアが最初から含まれてる
あれ、そうだった? だとしたら、UTF16は最初から破綻していたってことだな。
変なものを作らずにUTF32を導入すべきだった。
>UTF32に完全移行って何を移行するっていうんだ?互換性がないんだから
>既に使われてるものを簡単に変えられるわけがない。
シフトJISからUnicodeへも互換性がないのに移行が進んだだろ。
>UTF32が21bitコードになってしまったのはUTF-8のせいだ
UTF8は可変長だから、32ビットでも表そう思えば表せる。
21ビットになったのはUTF16のせい。
>21bitあれば209万7152文字を表現できるんだから異字体セレクタなしで十分収録できる
収録した記号は他にも色々あるし、U+F0000〜U+10FFFFは外字領域だし、
21ビットだけでは心許ない。
>>613
異字体セレクタは同じコードでもAdobe-Japan1とMoji_Johoで字体が違う
滅茶苦茶な欠陥規格だから、さっさと廃止した方が良い。
(1) 日本(JIS)では包摂されてた989(2): デフォルトの名無しさん [sage] 2020/07/01(水) 22:04:25.91 ID:21fnQhh9(1) AAS
「包摂」の概念を知らないといけないな。
「包摂 文字コード」で検索すると出てくるが、「そ」や「り」は一画で
書く場合と、二画で書く場合があるが、それは「同一の文字であって
字体が異なるだけ」とみなすのが「包摂」ということ。
「高」と「??」は別の文字と考えられ、「包摂」されていない。
すなわち文字コードも分けられている。これは、unicodeで規定された
以上、もう変えることはできない。